Groonga 6.0.3リリース
Groonga 6.0.3をリリースしました!
それぞれの環境毎のインストール方法: インストール
変更内容
主な変更点は以下の通りです。
- command version 3を導入しました
- インデックスを使わない場合の最適化によりbetween()を高速化しました
- 新規プラグインを2つ追加しました
- ウィンドウ関数をサポートしました
command version 3を導入しました
今回のリリースでは、コマンドバージョン3を導入しました。
Groongaにはコマンドにバージョンの概念があります。
従来は[HEADER, BODY]という形式でレスポンスを返していました。
> status
[[0,1464342851.826973,0.0002036094665527344],{"alloc_count":273,"starttime":1464342849,"start_time":1464342849,"uptime":2,"version":"6.0.3","n_queries":0,"cache_hit_rate":0.0,"command_version":1,"default_command_version":1,"max_command_version":3}]
コマンドバージョン 3を指定すると、レスポンスは次のようにオブジェクトリテラル形式となります。
> status --command_version 3
{"header":{"return_code":0,"start_time":1464342859.177147,"elapsed_time":0.0001118183135986328},"body":{"alloc_count":276,"starttime":1464342849,"start_time":1464342849,"uptime":10,"version":"6.0.3","n_queries":0,"cache_hit_rate":0.0,"command_version":3,"default_command_version":1,"max_command_version":3}}
コマンドバージョン 3がサポートされたことで、例えば、JavaScriptなどからレスポンスを扱いやすくなりますね。
インデックスを使わない場合の最適化によりbetween()を高速化しました
今回のリリースでは、インデックスを使わない場合の最適化によりbetween()を高速化することができました。
インデックスを使った場合は速かったのですが、それに比べるとインデックスを使わなかった時のパフォーマンスに問題がありました。 今回はそのパフォーマンスの問題が改善されています。
どれくらい改善されたかというのをベンチマークを示します。
テストケースには次のようなスキーマを使いました。
table_create Entries TABLE_NO_KEY
column_create Entries rank COLUMN_SCALAR Int32
インデックスを使わずに、シーケンシャルサーチが行われるケースです。
テストデータは千件から百万件の4つのパターンを用意しました。
- 1000件
- 10,000件
- 100,000件
- 1,000,000件
シーケンシャルな連番をrankとして設定されているデータです。
これに対して、次のようにbetween()を適用してみました。100件だけ範囲検索するケースです。
- 1000件(rankの値が500より大きく、600以下)
- 10,000件(rankの値が5000より大きく、5100以下)
- 100,000件(rankの値が50,000より大きく、50,100以下)
- 1,000,000件(rankの値が500,000より大きく、500,100以下)
クエリは例えば次のようなものです。
select Entries --cache no --filter 'between(rank, 500, "exclude", 600, "include")'
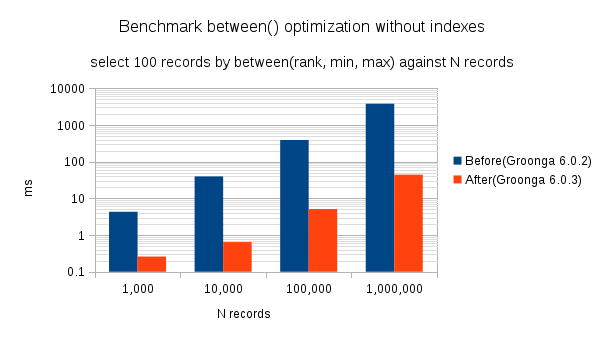
ベンチマークの結果は次のようになりました。10回実行した中央値をだしています。
| レコード数 | Groonga 6.0.2(ms) | Groonga 6.0.3(ms) |
|---|---|---|
| 1,000 | 4.3 | 0.2590 |
| 10,000 | 39.5 | 0.6440 |
| 100,000 | 390 | 5.1 |
| 1,000,000 | 3798.3 | 44.2 |
ぱっと見でもその違いがわかりますが、これを対数グラフ化するとこんな風になります。
新規プラグインを2つ追加しました
今回のリリースでは、新規プラグインが2つ追加されました。timeプラグインとnumberプラグインです。
どちらも、特定の範囲の値を同じ値とみなすことができるようになります。これにより、numberプラグインを使うと同一価格帯のものをまとめたりできます。
timeプラグインを使うと同時期のデータをまとめることができるようになります。
numberプラグインはnumber_classify関数を提供しています。
どんなふうに使えるのかサンプルを紹介します。価格がキーであるデータがいくつか登録されているとします。これを100円ごとのデータは同一価格帯の商品として分類してみましょう。 スキーマとサンプルは以下の通りです。
plugin_register functions/number
table_create Prices TABLE_PAT_KEY Int32
load --table Prices
[
{"_key": 0},
{"_key": 1},
{"_key": 99},
{"_key": 100},
{"_key": 101},
{"_key": 199},
{"_key": 200},
{"_key": 201}
]
number_classifyを使って実現するには次のようなクエリを実行します。
select Prices --sortby _id --limit -1 --output_columns '_key, number_classify(_key, 100)'
number_classify(_key, 100)は分類には_keyの値を使うこと、値の範囲は100区切りで分類する、というのを指定しています。
[
[
[8],
[
["_key","Int32"],
["number_classify",null]
],
[0,0],
[1,0],
[99,0],
[100,100],
[101,100],
[199,100],
[200,200],
[201,200]
]
]
100円ごと、なので100から199までは同一価格帯の100としてみなしていることがわかりますね。
timeプラグインも時刻に関して似たようなことができます。次のような分類用の関数を提供しています。
time_classify_secondtime_classify_minutetime_classify_hourtime_classify_daytime_classify_weektime_classify_monthtime_classify_year
こんどは10分ごとを同一のタイムスタンプだとみなして分類してみましょう。サンプルのスキーマとデータは次の通りです。
plugin_register functions/time
table_create Timestamps TABLE_PAT_KEY Time
load --table Timestamps
[
{"_key": "2016-05-05 22:29:59.999999"},
{"_key": "2016-05-05 22:30:00.000000"},
{"_key": "2016-05-05 22:30:00.000001"},
{"_key": "2016-05-05 22:39:59.999999"},
{"_key": "2016-05-05 22:40:00.000000"},
{"_key": "2016-05-05 22:40:00.000001"}
]
分ごとなので、time_classify_minuteを使います。次のようなクエリを実行してみましょう。
select Timestamps --sortby _id --limit -1 --output_columns '_key, time_classify_minute(_key, 10)'
結果はこんなふうになります。
[
[
[6],
[
["_key","Time"],
["time_classify_minute",null]
],
[1462454999.999999,1462454400.0],
[1462455000.0,1462455000.0],
[1462455000.000001,1462455000.0],
[1462455599.999999,1462455000.0],
[1462455600.0,1462455600.0],
[1462455600.000001,1462455600.0]
]
]
10分ごとなので、22:30分から22:39分までのデータが同一時刻(1462455000.0)としてみなされていることがわかります。
ウィンドウ関数をサポートしました
今回のリリースでは、ウィンドウ関数をサポートしました。
例えば、連番を振るrecord_numberを利用することができるようになりました。
サンプルのスキーマとデータは次の通りです。
table_create Items TABLE_HASH_KEY ShortText
column_create Items price COLUMN_SCALAR UInt32
load --table Items
[
{"_key": "item1", "price": 666},
{"_key": "item2", "price": 999},
{"_key": "item3", "price": 777},
{"_key": "item4", "price": 111},
{"_key": "item5", "price": 333},
{"_key": "item6", "price": 222}
]
これをもとに、価格の安い順だと何番目のレコードになるかを取得してみましょう。クエリは次のようになります。
select Items \
--columns[nth_record].stage initial \
--columns[nth_record].value 'record_number()' \
--columns[nth_record].type UInt32 \
--columns[nth_record].window.sort_keys price \
--output_columns '_key, price, nth_record'
動的カラムnth_recordにrecord_number()の値を設定しているのがポイントです。
[
[
[6],
[
["_key","ShortText"],
["price","UInt32"],
["nth_record","UInt32"]
],
["item1",666,4],
["item2",999,6],
["item3",777,5],
["item4",111,1],
["item5",333,3],
["item6",222,2]
]
]
それぞれのアイテムが価格の安い順だと何番目のレコードになっているのかがこれでわかります。
お知らせ
来月以降、以下のイベントが予定されています。
- MySQLとPostgreSQLと日本語全文検索2
- 2016-06-09(木)20:00 - 22:00 DMM.comラボ
- 「MySQLとPostgreSQLと日本語全文検索」の第2弾です。前回はMySQL・PostgreSQLの日本語全文検索機能を使ったことがない人向けの内容でしたが、今回は使ったことがある(触ってみたくらいで十分)人向けの内容です。まだ参加申し込みが可能です。
- Groongaで学ぶ全文検索 2016-06-17
- 2016-06-17(金)20:00 - 22:30 東京都渋谷区広尾1-1-39 恵比寿プライムスクエアタワー20階 (株式会社イーライセンスシステムズ)
- 予習復習なしで全文検索とGroongaについて学ぶことができるイベントです。内容は参加者にあわせてその場で決めるので、前の回に参加していないとついていけない、ということはありません。
興味があるイベントがあればぜひご参加ください!
さいごに
6.0.2からの詳細な変更点は6.0.3リリース 2016-05-29を確認してください。
それでは、Groongaでガンガン検索してください!
