
7.8.1. 概要#
Groongaにはテキストをトークナイズするトークナイザーモージュールがあります。次のケースのときにトークナイザーを使います。
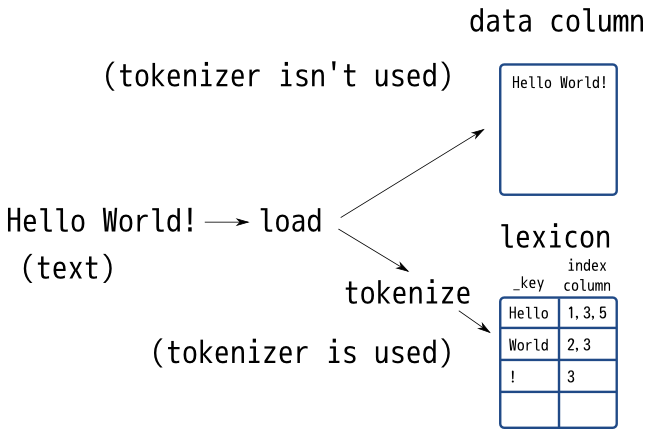
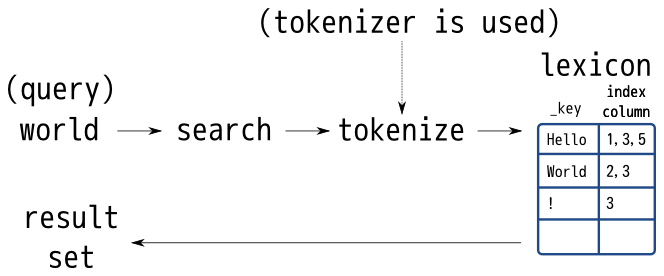
全文検索ではトークナイザーは重要なモジュールです。トークナイザーを変えることで 適合率と再現率 のトレードオフを調整することができます。
一般的に TokenBigram が適切なトークナイザーです。トークナイザーについてよく知らない場合は TokenBigram を使うことをオススメします。
tokenize コマンドと table_tokenize コマンドを使うことでトークナイザーを試すことができます。 tokenize コマンドを使って TokenBigram トークナイザーを試す例を以下に示します。
実行例:
tokenize TokenBigram "Hello World"
# [
# [
# 0,
# 1337566253.89858,
# 0.000355720520019531
# ],
# [
# {
# "value": "He",
# "position": 0,
# "force_prefix": false,
# "force_prefix_search": false
# },
# {
# "value": "el",
# "position": 1,
# "force_prefix": false,
# "force_prefix_search": false
# },
# {
# "value": "ll",
# "position": 2,
# "force_prefix": false,
# "force_prefix_search": false
# },
# {
# "value": "lo",
# "position": 3,
# "force_prefix": false,
# "force_prefix_search": false
# },
# {
# "value": "o ",
# "position": 4,
# "force_prefix": false,
# "force_prefix_search": false
# },
# {
# "value": " W",
# "position": 5,
# "force_prefix": false,
# "force_prefix_search": false
# },
# {
# "value": "Wo",
# "position": 6,
# "force_prefix": false,
# "force_prefix_search": false
# },
# {
# "value": "or",
# "position": 7,
# "force_prefix": false,
# "force_prefix_search": false
# },
# {
# "value": "rl",
# "position": 8,
# "force_prefix": false,
# "force_prefix_search": false
# },
# {
# "value": "ld",
# "position": 9,
# "force_prefix": false,
# "force_prefix_search": false
# },
# {
# "value": "d",
# "position": 10,
# "force_prefix": false,
# "force_prefix_search": false
# }
# ]
# ]
「トークナイズ」はテキストから0個以上のトークンを抽出する処理です。「トークナイズ」する方法はいくつかあります。
例えば、バイグラムというトークナイズ方法では Hello World は次のトークンにトークナイズされます。
He
el
ll
lo
o_(_は空白文字という意味)
_W(_は空白文字という意味)
Wo
or
rl
ld
上記の例では、 Hello World から10個のトークンを抽出しました。
例えば、空白区切りのトークナイズ方法では Hello World は次のトークンにトークナイズされます。
Hello
World
上記の例では、Hello World から2つのトークンを抽出しました。
トークンは検索時のキーとして使われます。使用したトークナイズ方法で抽出したトークンでしかインデックス化されたドキュメントを探すことはできません。例えば、トークナイズ方法としてバイグラムを使った場合は ll で Hello World を見つけることができます。しかし、空白区切りのトークナイズ方法を使ったときは ll で Hello World を見つけることはできません。なぜなら、空白区切りのトークナイズ方法は ll というトークンを抽出していないからです。空白区切りのトークナイズ方法は Hello というトークンと World というトークンしか抽出していません。
一般的に、小さいトークンを生成するトークナイズ方法は再現率が高い代わりに適合率が低くなりがちです。一方、大きいトークンを生成するトークナイズ方法は適合率が高い代わりに再現率が低くなりがちです。
例えば、バイグラムというトークナイズ方法では or で Hello World と A or B を検索できます。しかし、「論理和」を検索したい人にとっては Hello World は不要な結果です。これは、適合率が下がったということです。しかし、再現率は上がっています。
空白区切りのトークナイズ方法を使った場合は or で A or B だけが見つかります。なぜなら、空白区切りのトークナイズ方法では World は World という1つのトークンだけにトークナイズされるからです。これは、「論理和」を探したい人にとっては適合率が挙がっています。しかし、 Hello World も or を含んでいるのに見つかっていないので再現率が下がっています。